Artificial intelligence systems now play a central role in daily life, from medical diagnosis and content moderation to autonomous driving and AI agents that act on our behalf. As these systems take on more responsibility, they must become more trustworthy. In particular, they should recognize when they are uncertain, rather than giving confident answers in situations where they may be wrong. Recent examples of large models giving incorrect factual answers with high stated confidence illustrate the problem: neural networks can be confidently wrong, and in high-stakes settings that failure can be costly.
Bayesian deep learning offers one way to address this problem. A standard neural network stores a single fixed value for each weight, where weights are the numbers that determine how the model transforms inputs into predictions. In Bayesian deep learning, each weight is represented by a probability distribution instead. During training, the model learns not only a typical value for each weight, but also how uncertain that value is. At prediction time, this allows the model to express uncertainty, especially on inputs that differ from those seen during training.
The challenge is that this extra uncertainty comes at a high computational cost. In a common approach called mean-field variational inference, each weight is described by both a mean and a variance. This roughly doubles the number of learned parameters compared with an ordinary network, and also increases the cost of training and prediction. For small models this is manageable, but modern neural networks often contain hundreds of millions or billions of weights. At that scale, standard Bayesian methods can become too expensive to use in practice.
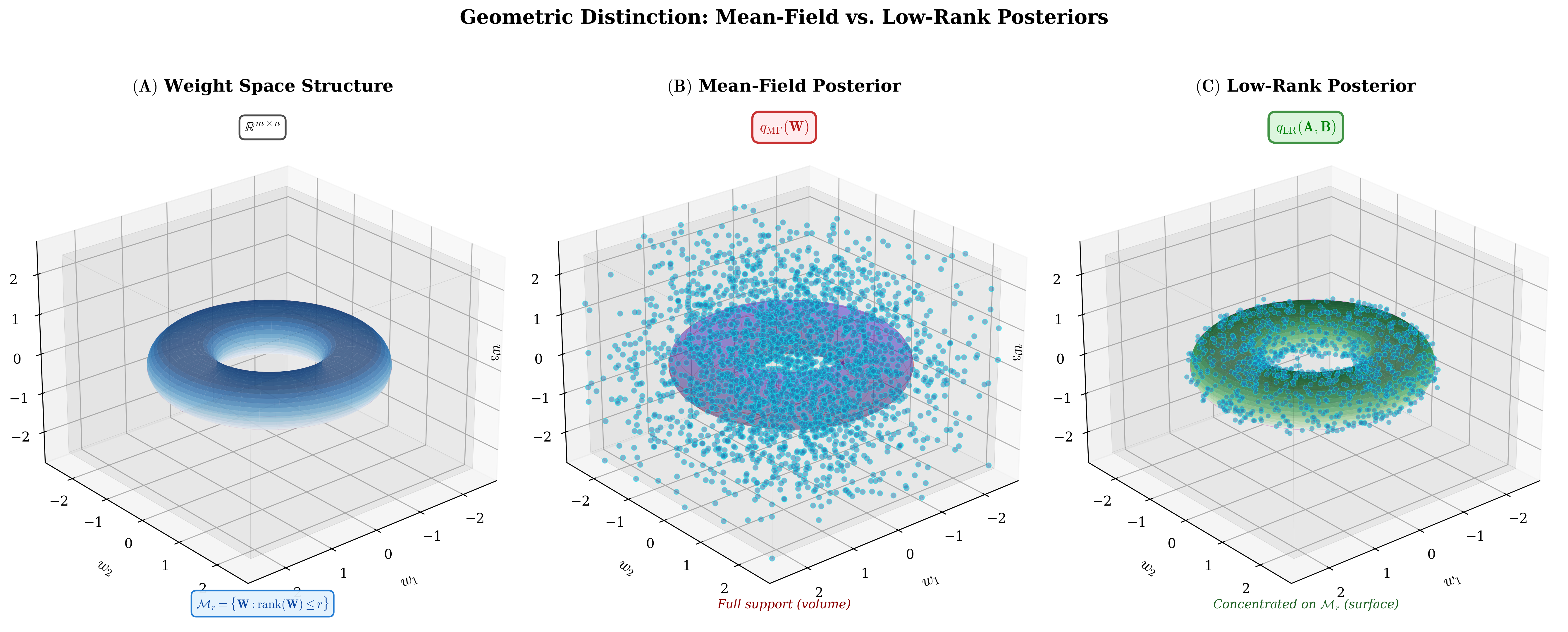
This paper introduces a low-rank factorization approach to overcome that barrier. Each layer's weights form a large matrix with \(m\) rows and \(n\) columns. Instead of storing this full matrix, we write it as the product of two smaller matrices that share a common inner dimension \(r\), called the rank. This reduces the number of parameters per layer from \(m \times n\) to \(r \times (m+n)\).
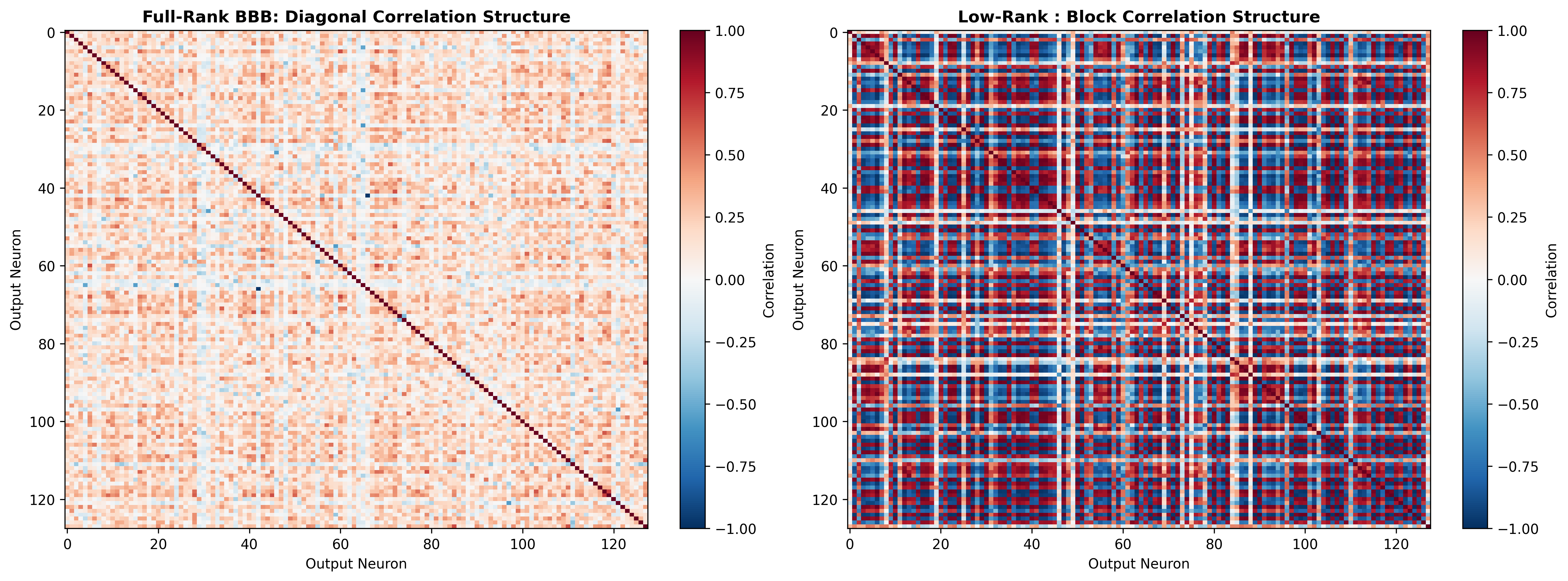
The rank \(r\) is a value we choose, and the smaller we can set it while preserving accuracy, the greater the saving. Many trained weight matrices exhibit rapid spectral decay, meaning that much of their structure is concentrated in a small number of dominant directions. Low-rank factorization can therefore preserve useful predictive structure while substantially reducing parameter count. It can also reduce memory and computation, especially at larger scales. As a further consequence, shared factors induce correlations between weights instead of treating every weight independently, enabling more structured propagation of uncertainty through the network.
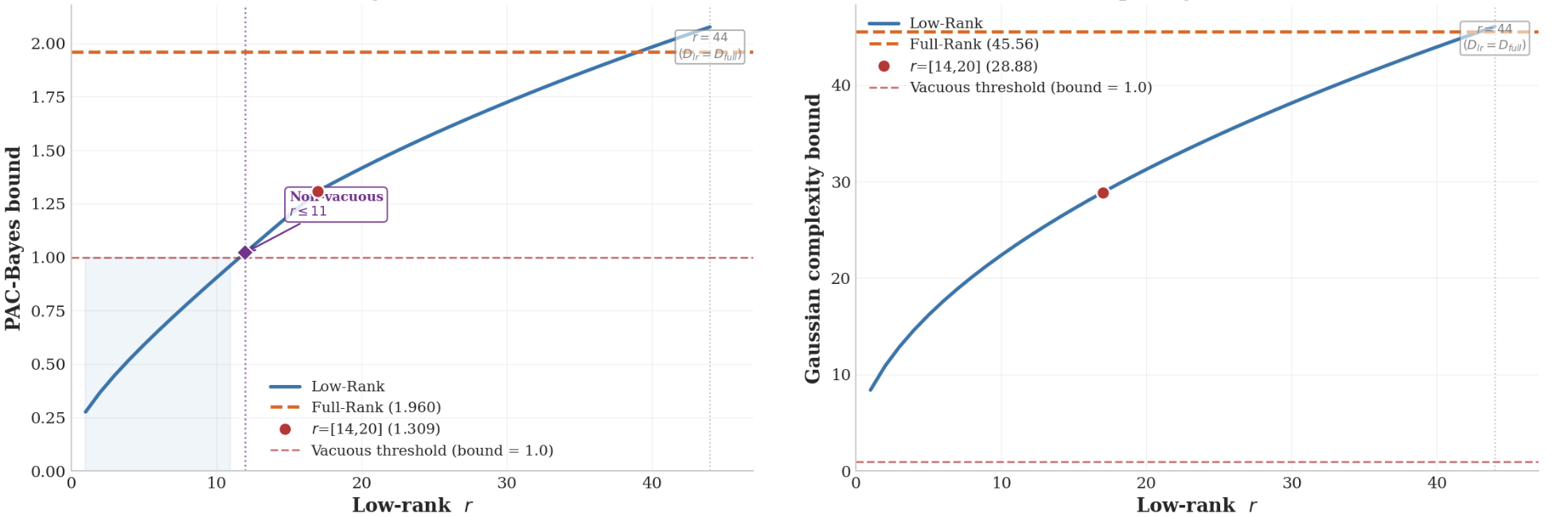
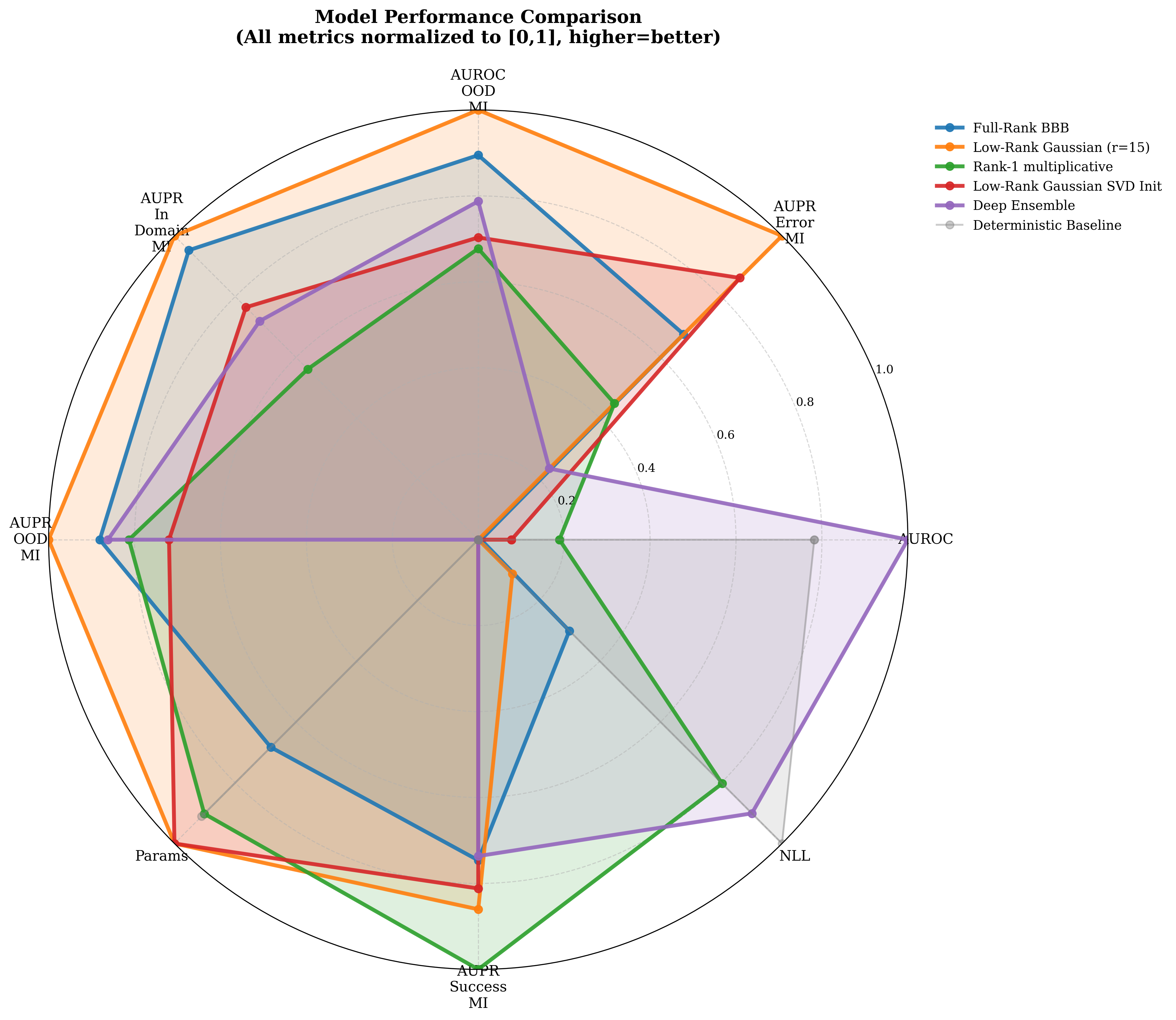
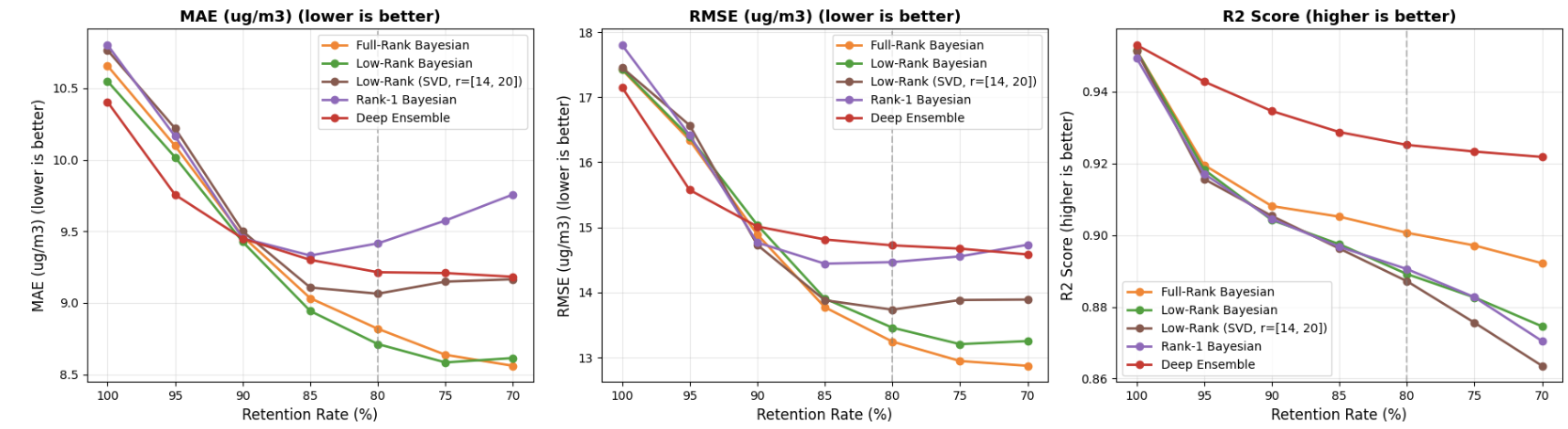
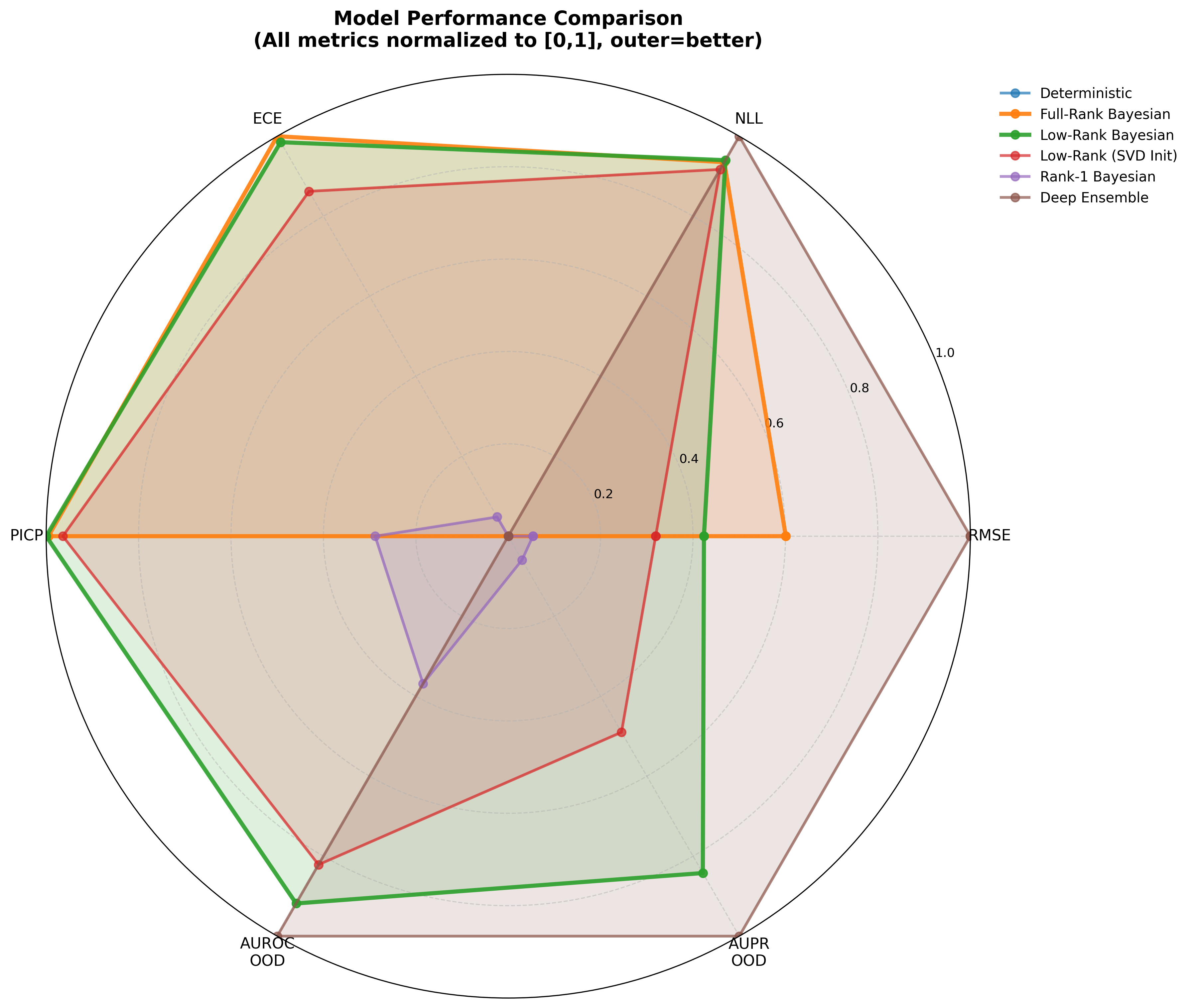
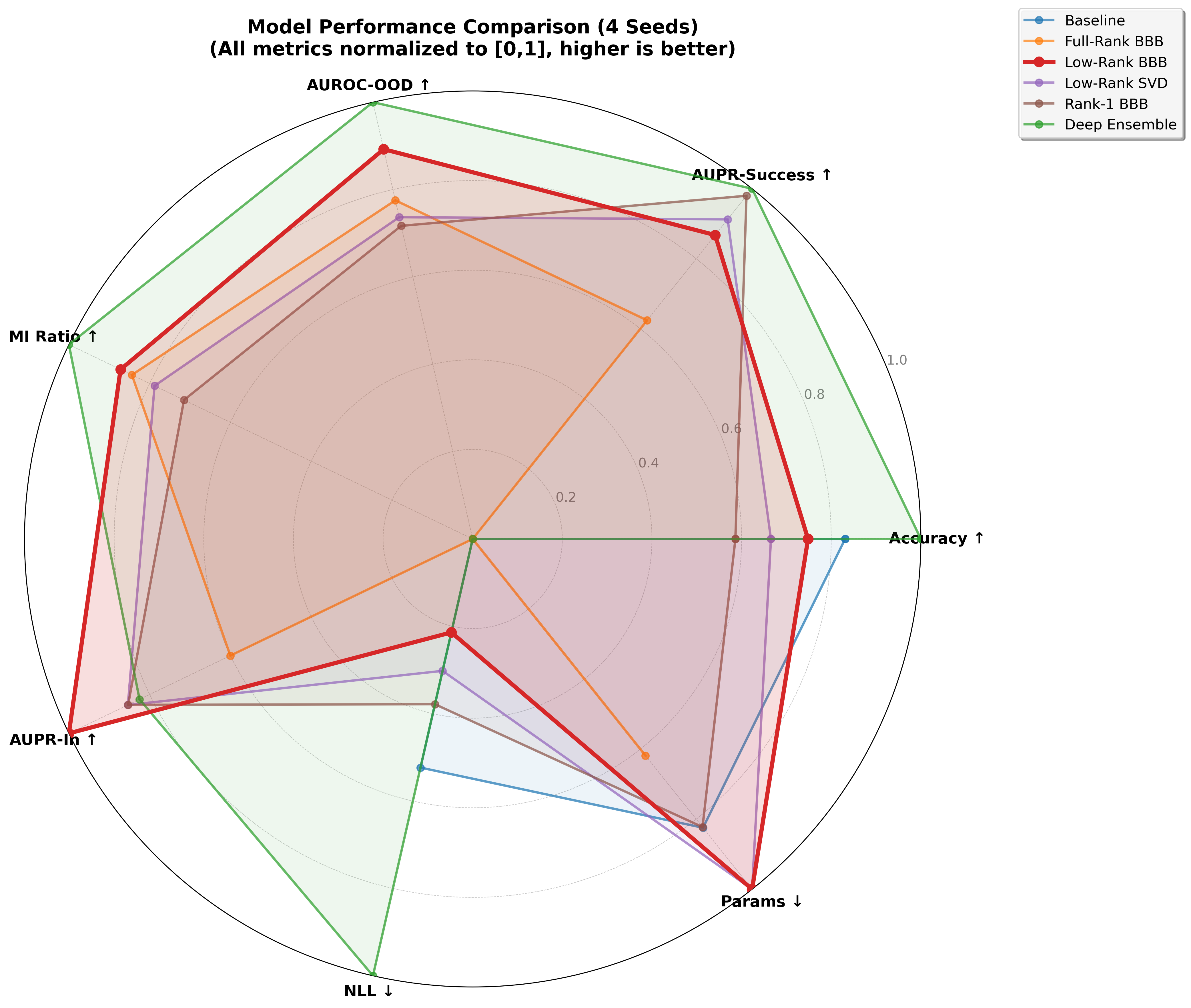
We prove that this is more than a convenient shortcut: the low-rank version carries generalization guarantees, with approximation error controlled by how quickly the matrix's minor directions fade out. We then test it on intensive-care mortality prediction, air-quality forecasting, and movie review sentiment classification. The low-rank model outperforms larger and more costly methods on several uncertainty metrics in key settings while using only a small fraction of their parameters. In one experiment, it uses approximately thirty-three times fewer parameters than an ensemble of five networks. It is particularly effective at identifying inputs that differ from its training data and at providing useful uncertainty under distribution shift.
Taken together, these results show that low-rank factorization provides a principled path toward scaling Bayesian deep learning to modern architectures. The resulting uncertainty-aware models are smaller, theoretically grounded, empirically competitive, and practical for high-stakes settings where trustworthy predictions matter most.